VEGA was used to predict liver toxicity of food preservatives in the last article. What does an AI model for liver toxicity look like? Since AI models provide results that are directly related to human safety, there are a number of guidelines for this. In particular, transparency of predictions is important issue. In the case of AI models like the one we used, users are curious to know key information to understand the model. In fact, if this is not disclosed, it is difficult to trust and use it.
A model that predicts experimental values from chemical structures is called a QSAR model. There is a form to report the details of this model, called the QMRF. This is an acronym for QSAR Model Reporting Format. VEGA records and discloses the QMRF information of the developed models in detail. So it's a highly transparent program.

In the Human Toxicology section, the models are categorized by type, and I found the details for the liver toxicity prediction model. In the image below, you can see the QMRF file of the liver toxicity prediction model at the bottom.
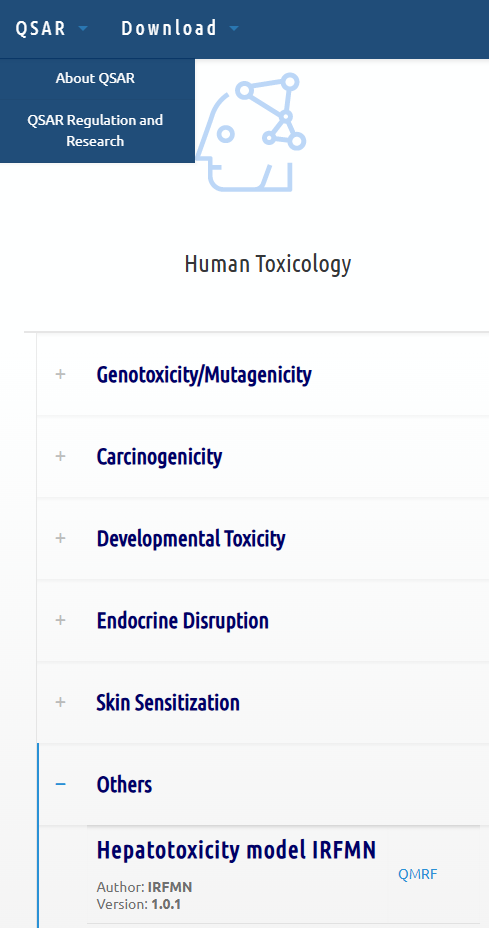
Click blue text 'QMRF' and a pdf file will open. This document reveals all the details of the model. On the first page have a brief description of the program. Pages 1 and 2 contain information about the developer and general information about the software.
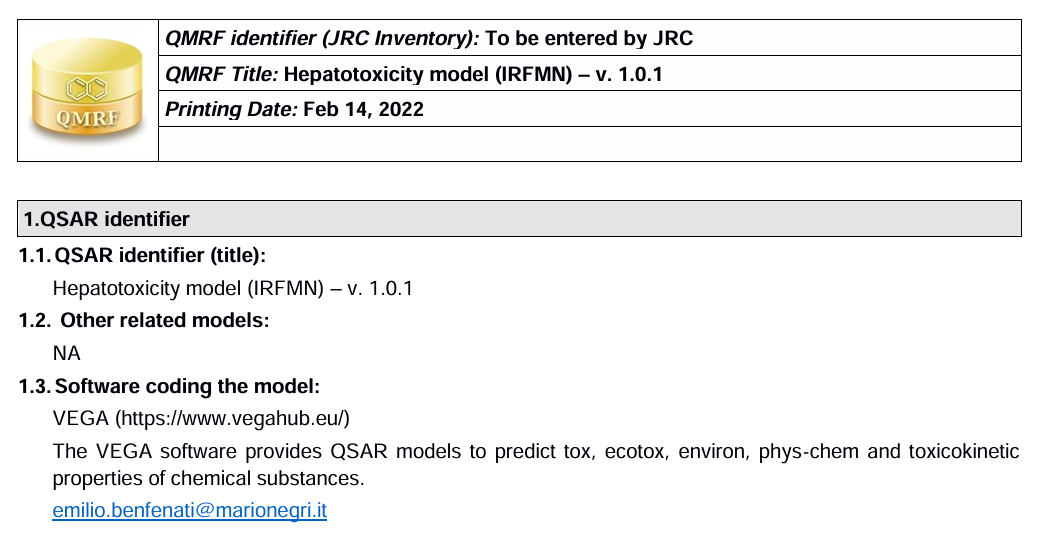
From number 3, it covers important information. You've probably heard the name OECD before, the Organization for Economic Development and Cooperation. OECD publishes a lot of documents related to chemical safety. It doesn't sound like it has anything to do with economics, but they publish them anyway. They also published a guideline on QSAR models. It defines five principles that should be followed to validate a QSAR model.
Guidance Document on the Validation of (Quantitative) Structure-Activity Relationship [(Q)SAR] Models
This document presents principles and helpful guides for validating (Q)SAR technology for a variety of applications.
www.oecd.org
A brief introduction to the five principles is as follows
1) What is the model predicting? A description of the experimental value. Experimental protocol to measure the data.
2) How was the model built? A description of the algorithms used in the development process.
3) Are the predictions reliable? An analysis of how reliable the model's predictions are.
4) How good was the fit? An analysis of the model's prediction accuracy
5) So what does the structure have to do with the experimental values? Relationship between the structural properties and the experimental values.
I suddenly wrote a lengthy explanation on OECD QSAR validation guideline because the QMRF organizes the details of the model according to this 5 principles. So, starting with paragraph #3, the model is described in detail in the context of the OECD validation guideline principles. Below are the details of the liver toxicity model. All data sources are disclosed.

Data is the key to AI model development. You are nothing without data even if you are the top-notch AI researcher. It's just impossible to reproduce the model. So, in many cases, the data is never published. That's why there are no programs that transparently disclose the details of their models, starting with the source of the data.
Can we get the dataset instead of just description? Yes. VEGA makes all the data available. There's a question mark on the left side of the model. Press this button and get the dataset.

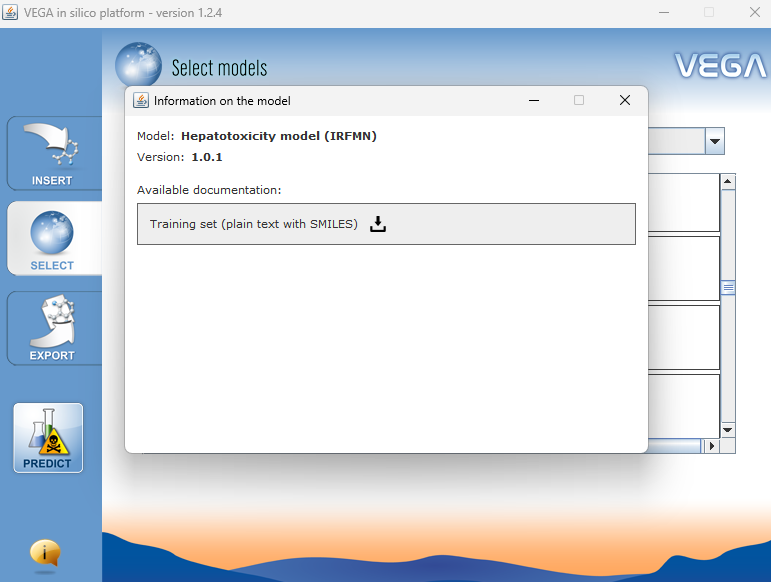
Click the question mark to download the training set from this window. This will save all the data used to develop the model. It will be saved as a txt file, and in Notepad it looks like this. The Status indicates which substance was used for training or test. There are the experimental values and the predicted values. With this information, it is easy to calcaulte the prediction accuracy of the VEGA model.
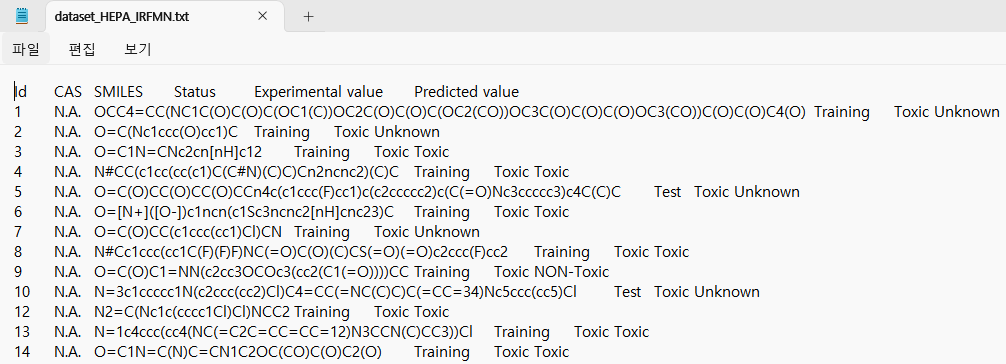
It is txt file, but you can open it in excel as well. As each piece of information is separated by regular intervals, it is better represented when opened in Excel, which automatically separates the columns.
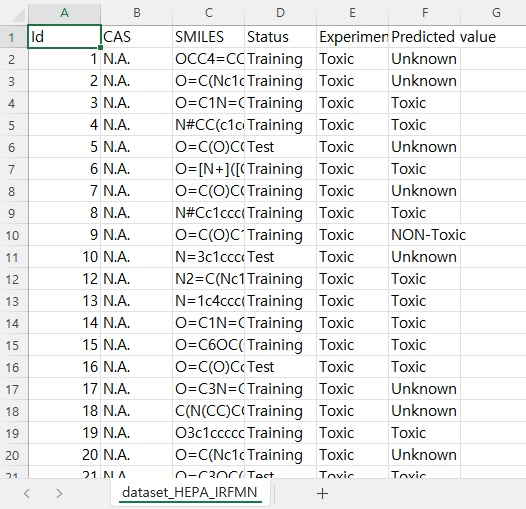
This is about data part of the model. Next post, I'll sumarize the second principle, the model development part.
'AI & Chemistry' 카테고리의 다른 글
| Is it really safe if AI says it is safe? (0) | 2024.11.18 |
|---|---|
| Is this really AI model? (Expert system vs chatGPT-o1 preview) (0) | 2024.11.17 |
| AI predicts liver toxiciy of food preservatives (1) | 2024.11.15 |
| Food preservatives are safe? (0) | 2024.11.13 |
| How can AI understand chemical substances? (0) | 2024.11.12 |