Can we trust AI's answer? Hallucinations are flooding in AI's answer... If you've been using ChatGPT for a while, you've probably experienced it at least once or twice. It's not uncommon to see ridiculous answers. Are toxicity prediction models any different? NO. They can say that a substance is dangerous when it's safe, or vice versa. You can just confirm the ChatGPT answers by googling... In case of toxicity prediction AI, predictions can be validated only through lab works. Some experiments take a month, some take half a year, some take two years... Is there a way to find out how reliable the model's answer is without waiting for 2 years?
The answer is in the data. Analyze the model's predictions based on the data used to train the model. This is the third principle of the OECD QSAR validation guideline. It says to check the applicability domain of the model. What is the applicability domain? It is the range over which the model can be applied to produce reliable results. What domain? The structural domain of a chemical. If the chemicals in the data used to train the model are similar to the new chemicals, the predictions are likely to be accurate. Therefore, the confidence of the prediction is based on the structure similarity between training data and the new chemicals.
The carcinogenicity of benzoic acid was predicted with VEGA. In the previous post, I was using liver toxicity results, but since there was no applicability domain analysis in the liver toxicity prediction reports, I switched to carcinogenicity. According to VEGA report, benzoic acid was already included in the dataset, so it directly provided the experimental values and it was confirmed that it is not a carcinogen. But...! The AI model's prediction said it is a “Carcinogen”. Which one should we believe between the experimental results and the predicted results? Obviously, the experimental results. But why would this model tell us that a safe substance is carcinogenic?
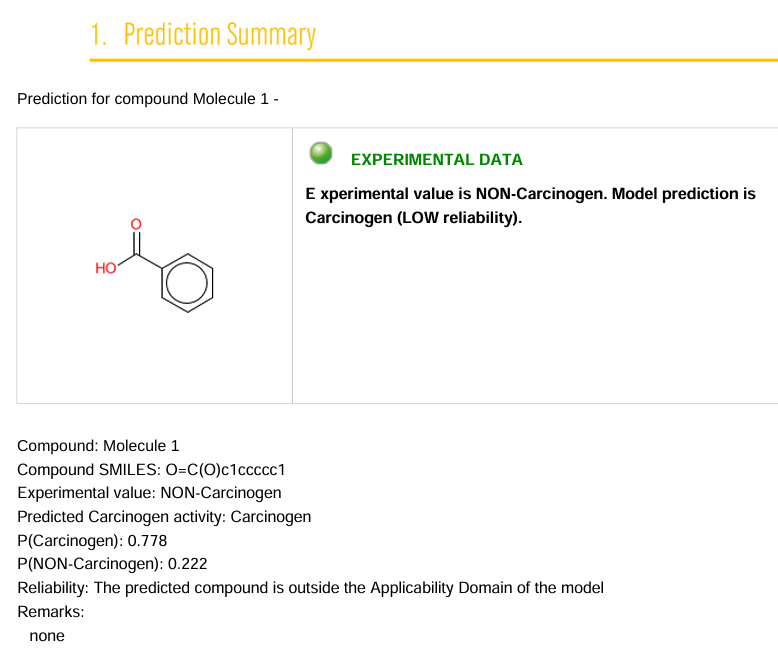
The prediction for benzoic acid was scored as likely to be carcinogenic by 0.778. Conversely, the score for non-carcinogenicity was 0.222. Normally, a value greater than 0.5 is reported as the final result. So benzoic acid was classified as a carcinogen. However, if you read the 'reliability' information below prediction, it says that the compound predicted is outside the applicability domain of the model. This means that you shouldn't trust the prediction. Let's look at the results of the coverage analysis.

The compound at the top is benzoic acid. The next five are substances that are similar to benzoic acid. This is the applicability domain analysis based on highly similar substances in the training data. First, we see that most of the substances that are similar to benzoic acid are not carcinogenic. The only exception is the last one, which is carcinogenic. Of all the similar substances, only prediction on benzoic acid is wrong, so why did the program conclude that we shouldn't trust its predictions? Below is a more detailed coverage analysis.
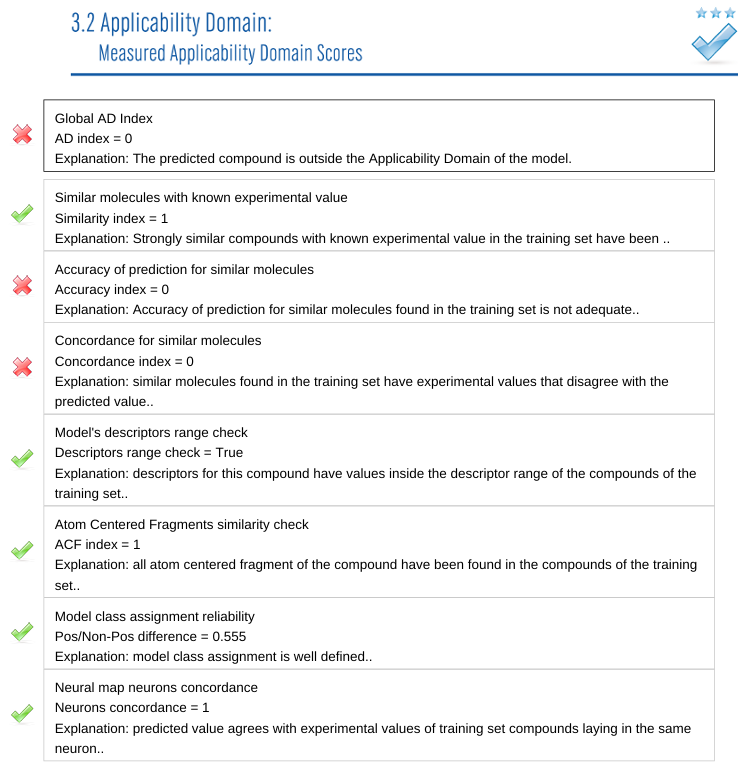
The first global AD index value is a final score. Benzoic acid received a score of 0. VEGA concluded that the AI model result was false. The followings are each index to check applicability domain of the model.
1) Are there similar chemicals in the model training data? There were a lot of very similar models, giving it a high score 1.
2) What is the prediction accuracy of similar compounds? The prediction accuracy of similar substances was poor, so this score is 0.
3) Do the experimental values of similar chemicals match the predicted values? Most of the similar chemicals were not carcinogenic, but the prediction of benzoic acid was carcinogenic. Therefore, it is not reliable because it was predicted to be completely different from similar chemicals. Therefore, it received a score of 0.
4) Check the feature value range of the model. After converting the chemicals into numerical values (descriptors), the AI model gives the result, which is a comparison of whether the converted values match the overall distribution of the data.
5) Identify molecular structure patterns. When a molecular structure is broken down into smaller pieces, various structural patterns can be found. This index checks if there were any unusual patterns in the user input.
6) The model calculates both the probability of toxicity and the probability of non toxicity, but is the difference between the two values large enough? If you see a number like 0.55 for toxicity and 0.45 for no toxicity, you might question the results. In the case of benzoic acid, this was not the case.
7) The last value is the result of clustering the data using a technique called Self-organizing map (SOM). It means that the experimental and predicted values of data in similar clusters match well.
VEGA ran various analyses to test reliability of the model's answer. VEGA concluded that you should not trust the AI model's answers on benzoic acid's carcinogenicity because it scored 0 on two items. (Out of applicability domain means you should not trust it.) There are always ways to verify the answers provided by the AI model. In the case of predicting the toxicity of chemicals, we can analyze the reliability of the results by comparing them with experimental values of similar structures in the training data. So please don't make a fuss saying you found a poison through AI.. Be sure to check out the applicability domain analysis.
'AI & Chemistry' 카테고리의 다른 글
| So? How accurate is AI? (0) | 2024.11.20 |
|---|---|
| How accurate is AI? (0) | 2024.11.19 |
| Is this really AI model? (Expert system vs chatGPT-o1 preview) (0) | 2024.11.17 |
| Dissecting an AI model (data) (2) | 2024.11.16 |
| AI predicts liver toxiciy of food preservatives (1) | 2024.11.15 |